
Deep Mapping and Path Planning
Keywords: Value Iteration Network, Graph Neural Network, Transformers, Mapping, Navigation.
Source Code: Github
In this project, we focus on the multi-robot navigation problem in a structured environment. At each time-step, each robot makes a partial observation of the surrounding environment and chooses an action to reach its goal position. Two robots can communicate if they are within the communication range of each other.
Several learning-based planners have been developed to solve this problem in an end-to-end manner. Most recent architectures employ a Convolutional Neural Network (CNN) to encode the robot observations, variants of Graph Neural Networks (GNN) to communicate messages, and a Multi-Layer Perceptron (MLP) to select the actions. However, these architectures only take into account the current observations, and hence cannot leverage the memory of what the team has observed in the past. Furthermore, a simple MLP for selecting the action is not expressive enough to solve the navigation task in a complex occupancy map where the optimal path to the goal is significantly longer than the straight-line distance from the goal. Consequently these models exhibit poor performance in the case of complex environments, e.g., a maze.
To this end, we present a new architecture that: (i) equips each robot with individual memory, which stores a compact representation of its belief of the occupancy status of the environment; and (ii) uses a Value Iteration Network (VIN) as the action selector module instead of an MLP. The memory works as an input to the VIN. Consequently, these two changes work in conjunction with each other.
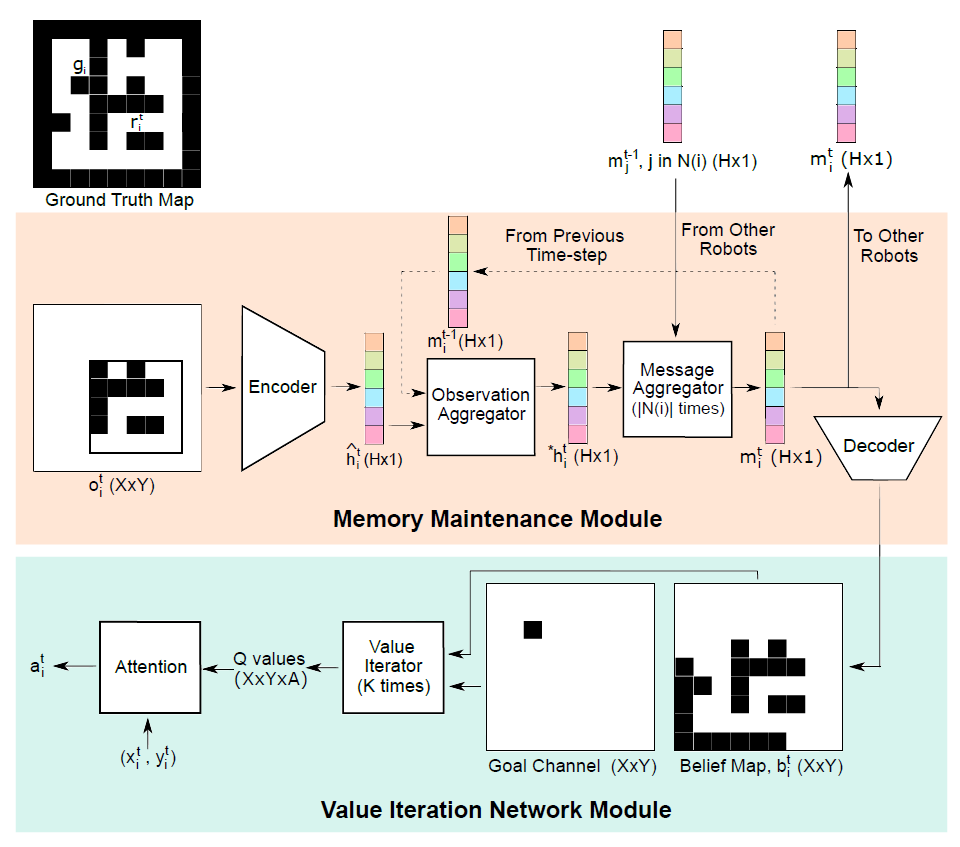
Our proposed architecture, shown in the above figure, maintains a compressed embedding for each robot, which represents the robot’s belief about the occupancy map of the environment. Two robots communicate their embeddings with each other when they are within the communication range. Exchanging embeddings, instead of the full map, helps reduce the communication overhead. The embeddings get updated with each observation made and with each message received from a neighboring robot. Given the occupancy grid and the destination as input, the planner imitates the value iteration process to select an action. The memory and planning modules can be trained end-to-end or separately in a supervised manner, which makes the architecture differentiable. We call this architecture Decentralized Differentiable Memory-enabled Mapping and Navigation (D2M2N). A simulation of single robot path planning using our proposed architecture, with a simplified version that does not include inter-robot communication, is shown in the video at the top of this page.
We have conducted extensive experimentation to evaluate the performance of D2M2N and compare it with the state-of-the-art architecture for multi-robot navigation, MAGAT, proposed by Li et al. The empirical results show that D2M2N outperforms MAGAT in both simple and complex maps, resulting in 5% and 30% increase in action selection accuracy respectively. We present results to show the effect of varying the embedding size. We also demonstrate how our model performs in the case of a noisy sensor model.
Publications
- Md Ishat-E-Rabban, Pratap Tokekar, D2M2N: Decentralized Differentiable Memory-Enabled Mapping and Navigation for Multiple Robots, arXiv preprint arXiv:2310.07070, 2023. paper